Back then in the university, I tended to enjoy the math courses. The first year though wasn’t great, I often lost points in exams merely because I made some pretty lame mistakes. I used to have monumentally bad handwriting so taking the effort to write/draw my math legibly made a gigantic difference. Neatness was a key factor in making my exams significantly less corrupted by errors.

Neatness is also a key factor when coming to design a solution architecture. It helps identifying systematic patterns, ones that you can repeat and eventually automate. Automation helps cloud operations teams reduce the volume of routine tasks that must be manually completed.
AWS SSO helps you securely connect your workforce identities and manage their permissions centrally across AWS accounts and possibly other business cloud applications. How can it fit into a solution that allows you to manage access at-scale? Let’s try to figure it out.
Figure-1 demonstrates a common use-case for an AWS SSO based solution architecture in a multi-account AWS environment:
- A developer login to the external identity provider (e.g., Okta) and launches the AWS App. assigned to her Okta‘s group.
- A successful login redirect the developer to AWS SSO console with a SAML2 assertion token. Depending on the developer’s association with Okta‘s user groups, the developer get to select a specific PermissionSet she is allowed to use in a specific AWS account.
- The developer uses the AWS IAM temporary credentials returned from the previous step to access AWS resources/services.

![]()
- A resource-based policy can result in a final decision of “Allow”, even if an implicit “Deny” in an identity-based policy, permissions boundary, or session policy is present (see AWS IAM Policy Evaluation Logic).
- AWS Single Sign-On (AWS SSO) is now called AWS IAM Identity Center.
Figure-2 visualizes user’s AWS access permissions that are granted by first adding users to groups in an an external identity provider, and then by creating tuples of group, AWS SSO PermissionSet and AWS account. In the absence of “Neatness” in place, aka, a solid model for these permissions’ assignments, it is clear how this can grow chaotically. For example, an implementation that includes 20 groups, 20 permission-sets and 20 accounts, can end up having 8,000 unique combinations that represent users’ permissions. What AWS permissions are granted to
User 2 when she is added to User-Group 2? In which accounts? It’s not so easy to figure it out. Not only security operations might be slowed down by this cumbersome process but it also makes things much more error-prone if humans have to manually configure it all.

Luckily, this is not too hard to solve.
The “AWS SSO Operator” Solution
We start by defining the conceptual model (see Figure-3) for managing our AWS SSO Permission-Sets Assignments. In addition to Neatness, the model also takes into account the Segregation of Duties principle and the advantage of isolating SDLC environments.

In this conceptual model, a user is associated with one or more job-functions. The model globally fixates the SDLC environments each job-function is allowed to access, e.g., the ‘tester’ job-function is limited to development and staging environments only. Each user is assigned to zero or more user-groups. Each user-group is associated with a single unique combination of job-function and workload. Each PermissionSet is associated with only one job-function but one-or-more workloads. Each account on the other hand, is associated with a single unique combination of workload and SDLC environment.
It simply means that user-groups, PermissionSets and accounts are associated based on their workload, job-function and SDLC environment attributions.
The model may change according to your company needs and policies. Companies choose to define and implement SDLC environments slightly differently. Job-functions also varies from one company to another. Thus it is important to keep the model highly configurable.
Figure-4 demonstrates the realization of the model and the matching process by which AWS SSO PermissionSet Assignments are created.

![]()
- User-groups follow a naming convention, a syntax, that incorporates job-function and workload identifiers in their names. User profile attributes (e.g., ‘team’, ‘project’) may also be implemented to enable ABAC for finer grained permissions.
- Each AWS SSO PermissionSet is tagged with ‘workloads’, a list of one or more workload names. Reserved values allows us to keep this list short by indicating the population of workloads to use, e.g.:
- workload_all – the PermissionSet matches all workloads
- workload_match – the PermissionSet matches multiple pairs of workload and user-group that share the same workload identifier.
- There is a special treatment for Sandbox accounts, which are assigned to a single owner.
- Each AWS SSO PermissionSet is also tagged with ‘job_function’, which semantically is similar to an AWS IAM Job Function.
- Each AWS Account is tagged with ‘workload’.
- Each AWS Account can represent a single workload only.
- AWS Organizational Units (OUs) in the second level of the hierarchy use reserved names that represent the SDLC environments your company uses.
- More on the “awsssooperator” workload is coming next..
Now that our model is implemented and can be used to systematically produce AWS SSO PermissionSet Assignments, wouldn’t it be nice to automate everything? Figure-5 presents the “AWS SSO Operator”, an opinionated solution, that automates the provisioning/de-provisioning of AWS SSO PermissionSet Assignments using the metadata from our implemented model. It keeps the AWS SSO PermissionSet Assignments in-sync with the model pretty much at all times. It continuously evaluates the actual PermissionSet Assignments state against the desired state and acts to remediate the gap.

The main two flows are divided by “event-based” and “time-based” triggers. They perform similar logic except the time-based one (B) run periodically and it analyzes the entire model to ensure the AWS SSO PermissionSet Assignments are in their desired state so it can initiate remediation actions as needed. The event-based flow (A), analyze and remediate only the AWS SSO PermissionSet Assignments that are in the context of the event. The main steps for the PermissionSet Assignments event-based flow:
- Perform cross-region event re-routing for the AWS Organizations MoveAccount event. This is only required if your AWS SSO Operator runs in a region other than N. Virginia. A separate SAM application is used for this purpose.
- Event Rules are implemented in AWS CloudWatch Events (similar to AWS EventBridge) to intercept the relevant events and target them to the appropriate AWS Lambda Functions (“Event Handlers”), e.g., MoveAccount (organizations.amazonaws.com), TagResource (source: sso.amazonaws.com), etc.
- AWS Lambda Functions, retrieve Okta & AWS SSO SCIM access tokens. The Event Handlers need those to access Okta and AWS SSO SCIM API.
- Okta user-groups are loaded by the event handlers so they can be matched against AWS SSO PermissionSets and AWS accounts based on their model’s attributes (aka, job-function, workload and SDLC environment). At the time of writing this post AWS SSO SCIM API is still limited and therefore, Okta API is used to iterate over the entire Okta user-group list.
- Verify that the user-groups we loaded from Okta exists in AWS SSO SCIM, otherwise we ignore them.
- Retrieve the AWS account workload tag and its parent OU (SDLC environment) so it can be matched by workload and job-function (job-functions are restricted to specific SDLC environments)
- AWS SSO API is used to create / delete PermissionSet Assignments. The API is asynchronous and need to be monitored.
- The PermissionSet Assignment request (create/delete) events are sent to AWS SQS (“PermissionSet Assignments Monitoring”), so they can be monitored asynchronously.
The PermissionSet Assignments Monitoring flow (3rd flow; C) sends audit events to SecOps (or to a SIEM system for this matter). Each event includes information about provisioning/de-provisioning a PermissionSet Assignment:
- The SQS2StepFunc Lambda Function is triggered to receive batches of messages from the AWS SQS queue to which steps A8 and B7 from previous flows send audit events.
- The Lambda Function starts executing the “Monitor Provisioning Status” AWS Step Functions. Figure-6 presents the corresponding state machine. The state machine process the events one by one by using the Map construct of AWS Steps Function.
- If the PermissionSet provisioning status is not final (aka, “in-progress” and neither “succeed” nor “failed”), then the state machine continues polling the status from AWS SSO.
- Eventually the final PermissionSet provisioning status is reported back to SecOps/CloudOps by publishing an AWS SNS message.

![]()
- The AWS SSO Operator does not mandate the use of SAML-Assertion / User-Attributes based ABAC but it is definitely something to consider when implementing fine-grained permissions at-scale as it significantly helps lowering the number of user-groups. For example, let’s assume we have a “Team” user attribute in Okta. Users of “Team_Alpha” and “cloudops_workload_myapp” user-group may have access to the AWS S3 object S3://some-bucket/some-key/myobj (production account; workload “myapp”), while users of “Team_Bravo” in the same user-group, may not.
- To speed up the development, the AWS SSO Operator solution is written as a couple of standalone Python modules that can be easily tested locally and then deployed as Lambda Function Layers keeping the Lambda functions code lean and as a mere protocol wrapper only. For infrastructure-as-code AWS SAM is being used.
- The Serverless application and the code are designed to avoid the limitations of the (Okta and AWS) API in use like rate-limits. It uses queues to buffer API calls, batch processing, caching, etc.
- The AWS SSO Operator has a built-in error handling that makes use of a Dead-Letter-Queue (AWS SQS) that it uses to surface operational errors to CloudOps personnel.
- You can now administer AWS SSO from a delegated member account of your AWS Organizations. This is a major advantage as you no longer need to login to the highly sensitive master account in order to use AWS SSO.
- AWS SSO PermissionSets may also be used to implement a secure remote access to AWS EC2 instances via AWS Systems Manager Session Manager. If you choose to use a different vendor/service (e.g., zscaler) for remote access, you would need to handle the permissions’ assignments separately.
The AWS SSO Operator and the model it introduces allow administrators of the external identity provider (e.g., Okta) to define user-groups with clear semantic of how those groups associated with AWS SSO PermissionSets and AWS accounts. Finally, the association of the AWS permissions to user-groups and accounts, is done automatically, which makes things more productive and more secure as it reduces the human risk factor.
Thoughts About Permissions Management
Up until now we took care of connecting the dots, assigning permissions to users by associating user-groups, AWS SSO PermissionSets and AWS accounts. But what about the actual permissions? Is there a way to automatically generate the exact least-privilege permissions required for a given job-function and the relevant workloads? Unfortunately, there is still no silver bullet to fully address this challenge.

And yet that does not mean we need to give up security, scale or speed – there is a lot we can do.
Permissions are implemented as AWS IAM policies attached to AWS SSO PermissionSets, AWS Organizations SCPs (or/and AWS Control Tower Preventive Guardrails), AWS Resource-based policies, AWS Session policies and IAM permissions boundaries. The AWS Policy Evaluation Logic uses all of these policies to determine whether permission to access a resource is allowed or denied.
Managing permissions is not a one team show, there are multiple parties responsible for making this process of handling requests for permissions secure and effective at scale. Responsibilities may vary depending on the operating model of your company but usually there are three roles involved:
- Engineering is responsible for developing the application and raise their access requirements to the Cloud Infrastructure Security role.
Any delay in granting the permissions these users need would impact their ability to deliver on time. - Cloud Infrastructure Security is responsible for defining and implementing (via CI/CD and Infrastructure-as-code) the AWS SSO PermissionSets and the corresponding IAM policies.
- IT is responsible for implementing and operating the external identity provider (e.g., Okta). That includes provisioning of users, user-groups and adding/removing users to/from user-groups.
Our permission assignments model assists the IT team in managing user-groups and users at scale. The naming convention, the syntax, we use for user-groups helps to eliminate ambiguity and it also opens the door for new automations to follow.
The Cloud Infrastructure Security team however, owns the implementation and the responsibility to enforce the least privilege principal. Numerous requests for cloud permissions take place daily and they are expected to be handled almost immediately. The Cloud Infrastructure Security team is the one to handle these requests usually by hand-crafting AWS IAM policies, which are iteratively tested and corrected as needed. This process is manual, time-consuming, inconsistent, and often suffers from trial and error repetition. Our model force a certain order, IAM policies are defined for job-functions in the context of workloads, and to a some extent that eases the process since the job-function must be well defined. Still, this process is quite cumbersome and the Cloud Infrastructure Security might quickly become a bottleneck here.
![]()
- The Cloud Infrastructure Security and the IT teams shall handle permissions revocations in cases where a permission is unused or/and a user is no longer entitled to have it, e.g., due to user de-activation. The way to automate this process is not covered here and it deserves its own post.
- The services and actions of an IAM policy are determined in accordance with the job-function definition.
As the company scales, this kind of centralized and manual management approach falls over, becoming impractical for both operations teams and their users.
The following strategies, which are not mutual exclusive, can become handy to effectively operate permissions at-scale.
Decentralized Permissions Management
Managing permissions centrally may work for small businesses, but it does not scale very well, which is why you would want to have the option to delegate most of it to applications owners who can become more independent. There are multiple ways you could choose from to implement the delegation model but the one that keeps your application owners autonomous is probably preferred especially when these application members are also accountable for the business outcome. Since the AWS SSO Operator solution takes care of permissions’ assignments to user-groups and workloads, the delegated application team members would only need to manage the lifecycle of AWS SSO Permission-Sets (create/update/delete) and only the ones they are entitle to manage (specific workloads, job-functions). Figure-7 demonstrates permission delegation to a SecOps job-function of the “myapp” workload. A more detailed example of how permission delegation works in AWS SSO can be found here.

![]()
- The decentralized permissions management does not mean nothing is managed centrally. Certain operational aspects of the AWS SSO are likely to be still managed centrally by your Cloud Infrastructure Security team. For example,
- Permission delegation and policies like the one illustrated in Figure-7
- ABAC attribute mapping to SAML2 attributes from your external identity provider
- Cross-Functional job-functions’ permissions, e.g., secops, security-auditor, finops, support-ops, etc.
- AWS SSO Permission boundaries, which allows us to limit the permissions we delegate.
- None of the AWS SSO Operator responsibilities around permissions’ assignments & provisioning are delegated to anyone – only the AWS SSO Operator is entitled to handle that.
“Shift-Left”
Moving security and specifically permission management aspects to an earlier stage of the development lifecycle makes it easier to put more automation in place and therefore improve your ability to scale. Shifting left in this case would mean to scan, inspect and identify IAM policies security issues right in their IDE or CI pipelines. You want to detect and remediate, as early as possible, overly permissive IAM policies that might allow unintentional capabilities such as privilege escalation, exposure of resources, data exfiltration, credentials exposure, infrastructure modification, etc. A tool like Cloudsplaining, can be integrated into your CI/CD and fail builds that contain such security issues. Similarly, AWS IAM Access Analyzer can be integrated into your CI/CD (as in this example) to validate IAM policies against AWS security best practices and detect security issues including those associated with the principle of least privilege. Checkov is a static analysis tool for infrastructure-as-code (IaC) and it can also be integrated into your CI/CD to run security checks. Checkov is also integrated with Cloudsplaining to add more IAM checks that flag overly permissive IAM policies in IaC templates.
If you seek for best practices around how to automate testing for IAM policies, AWS IAM Policy Simulator can be integrated into your CI/CD for unit testing the IAM policies (as in this example) making sure they are fully functional in the context of the target accounts (e.g., is there an SCP blocking a service or action you plan to use?). The AWS IAM Policy Simulator is useful for testing the policies and to identify permission errors early in the development lifecycle. The AWS IAM Policy Simulator is not designed to assist with the least-privilege principle, however, when we come to implement this principle the chances for errors increase and we want to make sure our tightened policies still work.
These are just examples for tools that can assist in pushing some elements of permission management to the early phases of the development lifecycle in a scalable manner.
Permissions Boundaries
Another useful technique that helps with the least-privilege principle is to set hard boundaries to policies so no matter what permissions a policy declares, the effective permissions can never go beyond what is whitelisted by the permission boundaries. This measure is highly effective in gaining back control over permissions that are granted at high scale. AWS SSO PermissionSet allows defining permission boundaries to limit its policies. AWS Control Tower supports permission-boundaries for the entire organization in the form of preventive Guardrails and Custom Guardrails (which are implemented as AWS Organizations SCPs). AWS IAM support permission boundaries for IAM Roles/Users. Another type of “permission-boundaries” is controlled via AWS account level configuration by which we can block certain permissions for the entire account, e.g., block public access to all AWS S3 buckets within an AWS account.
Permission boundaries are crucial for the success of decentralized permission management. These are preventative controls that helps to ensure the delegated teams cannot go too wrong. The Cloud Infrastructure Security team is a good candidate to own the management of permissions boundaries and AWS Control Tower preventive Guardrails in particular.
Permissions Monitoring
Detective controls includes security monitoring tools, which can also become handy in supporting the least-privilege principle. More importantly, these security monitoring tools are there to ensure your security compliance requirements are met. It provides you with the capability to automatically detect permission related issues and respond to them by taking automatic/manual remediation actions. Figure-8 illustrates a common way of doing that on AWS.

AWS GuardDuty, AWS IAM Access Analyzer and AWS Config support permission related pre-defined checks. AWS Config also support custom rules for custom checks. These are high level services that require minimal or no coding at all. Don’t miss the opportunity to win quick wins!
You can also use any of the log events ingested to our SIEM (e.g., AWS CloudTrail, CloudWatch Logs, etc.) to detect security events. The AWS SSO Operator implements a very simple monitoring for the AWS SSO PermissionSet assignments and provisioning activities. The solution can be extended to send these logs to a SIEM and for example verify if “break-glass” or “power-user” permissions are assigned to inappropriate user-groups.
![]()
- Continuous permissions checks followed by corrective actions are best handled locally from within the account where the issues are found, aka, in a decentralized manner (see example). This is in contrast to the centralized approach that is illustrated in Figure-8 where security events are propagated to other systems, e.g., SIEM.
- Continuous permissions corrective actions may pose another challenge since permissions are most likely managed as source code (IaC) in a source control repository, which is also the source of truth. The challenge in this case is keeping the source code in-sync with the corrected permissions.
Define Permissions Based on Usage Analysis
Reverse-engineering is the act of dismantling an object to see how it works. It is done primarily to analyze and gain knowledge about the way something works but often is used to duplicate or enhance the object.
AWS IAM Access Analyzer generates IAM policies in a process similar to reverse engineering. It analyzes the identity historical AWS CloudTrail events and generates a corresponding policy based on the access activity. You should not consider the generated policy as the final product but it is still much better than nothing. The generated policy requires tuning like adding/removing permissions, specifying resources, adding conditions to the policy, etc.
Let’s assume we want to generate a policy for the job-function CloudOps. We will start by creating another job-function, e.g., CloudOpsTest, that in order to lower the risk, is enabled in development environments only. Then, we create an overly permissive AWS SSO PermissionSet for that job-function and for only a limited period of time during which an identity with that job-function uses the PermissionSet to execute playbooks / runbooks the CloudOps job-function is required to support. Once we are done, similar to reverse-engineering, based on all the actions we performed, we can now generate an IAM policy that would reflect the services and actions CloudOps would need to do her job. Last but not least, we fine-tune the generated policy by specifying resources, adding conditions, etc. Ta-da!
Not only AWS IAM Access Analyzer makes it easier to implement least privilege permissions by generating IAM policies based on access activity, but it also saves time trying to hand-craft the PermissionSet policy and figuring out what services and actions shall be included.
![]()
- Over-permissive policies are often used in non-production accounts for test purposes to minimize the effort of securing least-privilege access
- This is an iterative process as job-function requirements and the infrastructure used by workloads evolve all the time.
Using ABAC For Fine-Grained Permissions
Imagine your workload is maintained by two different application teams. Each team is responsible for different datasets, which are stored in the same AWS S3 bucket. Each team has its own CloudOps who is responsible for operating the production environments. The permission assignment model we introduced earlier, would assign the same permissions to each of the CloudOps. This is simply because they share the same workload and the same job-function. How can we implement finer-grained permissions for CloudOps so each can only access data belonging to her team? One option would be to split the job-function into two (e.g., CloudOpsTeamOne) and use two separated PermissionSets. But that does not scale well. Another option, which scales better, would be to take the ABAC approach by using user-attribute and AWS resource tag to limit access based on their values. Figure-9 demonstrates a policy that implements the desired ABAC for our fictitious use-case.

Conclusion
The AWS SSO Operator solution allows you to automate the assignment of AWS Permissions to user-groups and workloads. The AWS SSO Operator reduces some operational overhead and it makes things more more secure as it reduces the human risk factor
On the other hand, managing AWS SSO Permissions while adhering to the least privilege principal requires a more holistic strategy. There are some pragmatic measures you can take to operate and manage permissions at-scale while improving your security posture in this area too. It is not entirely unlikely that we’ll soon start seeing solutions/services from vendors automating permissions monitoring, provisioning and adjustments making it simple to follow the principle of least privilege (PoLP). Till then, make sure you have a solid story around it.
All the security controls you put in place meant to address the business risks you have identified. Not all applications and businesses are equally sensitive, thus, you should not invest in fancy solutions without being able to identify the risk you are trying to mitigate and how significant it is for your business.



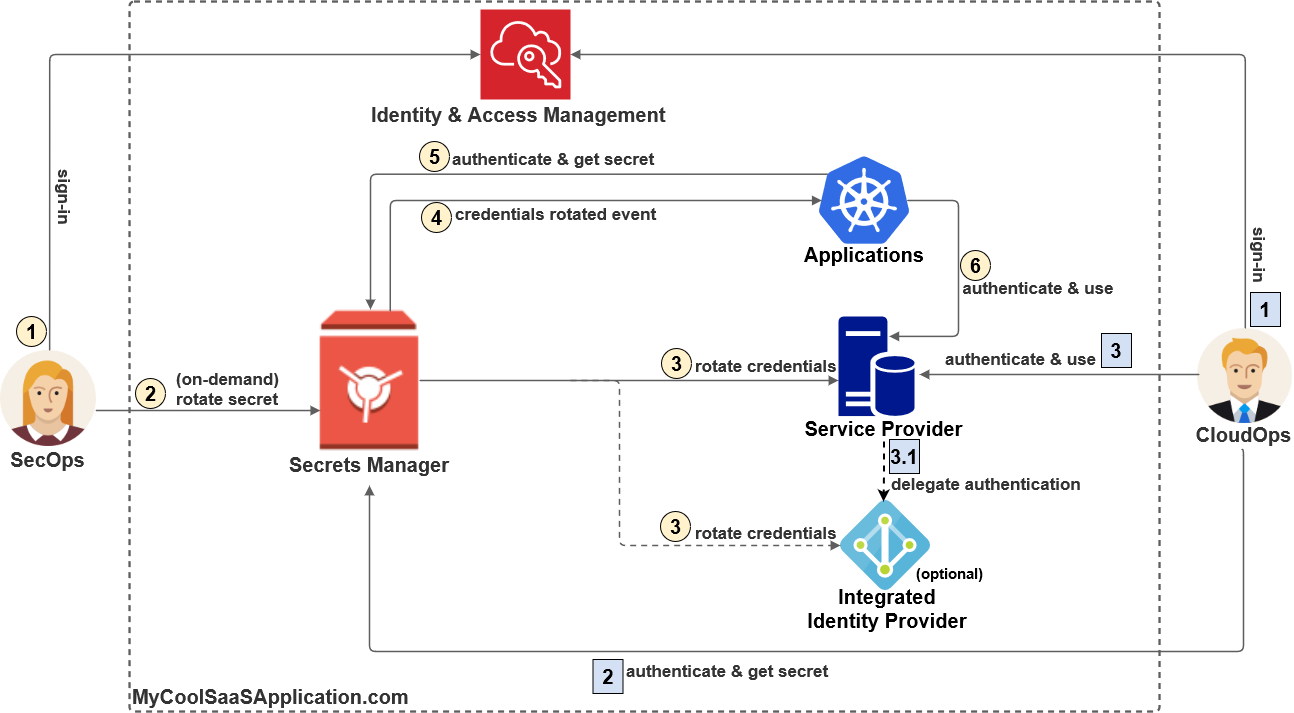
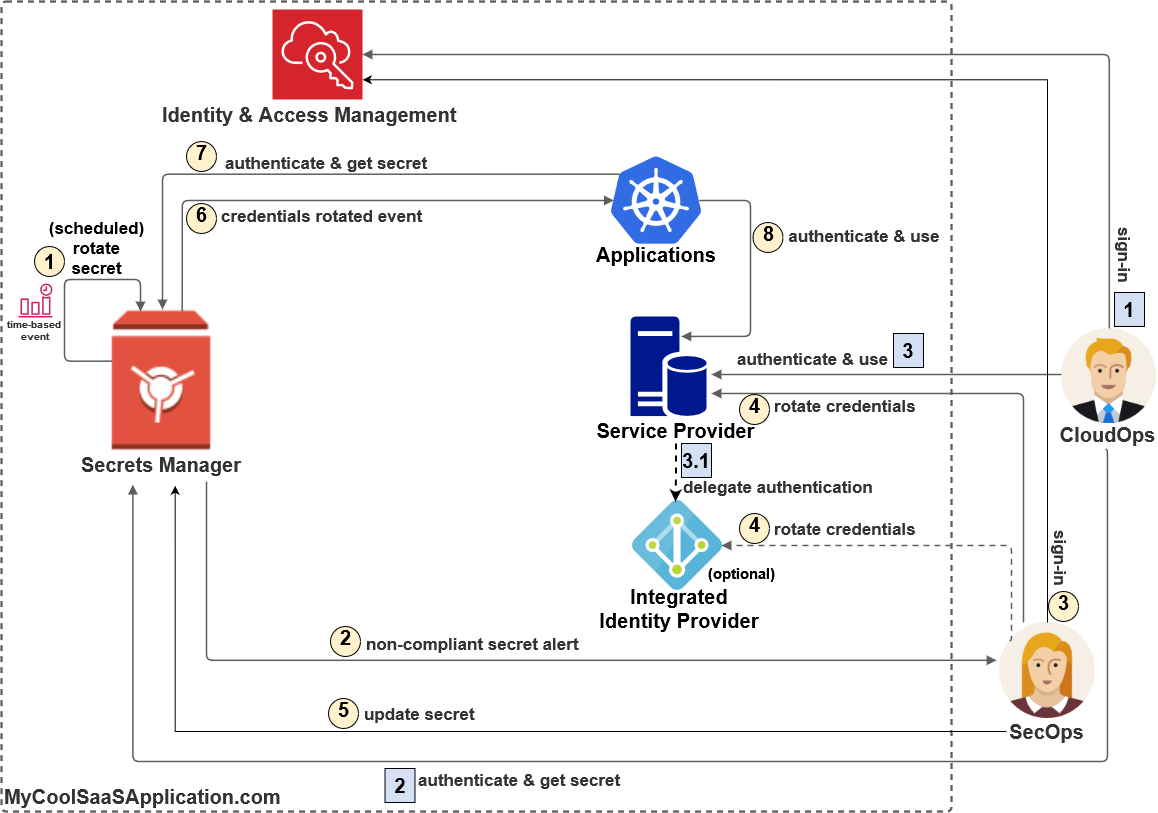
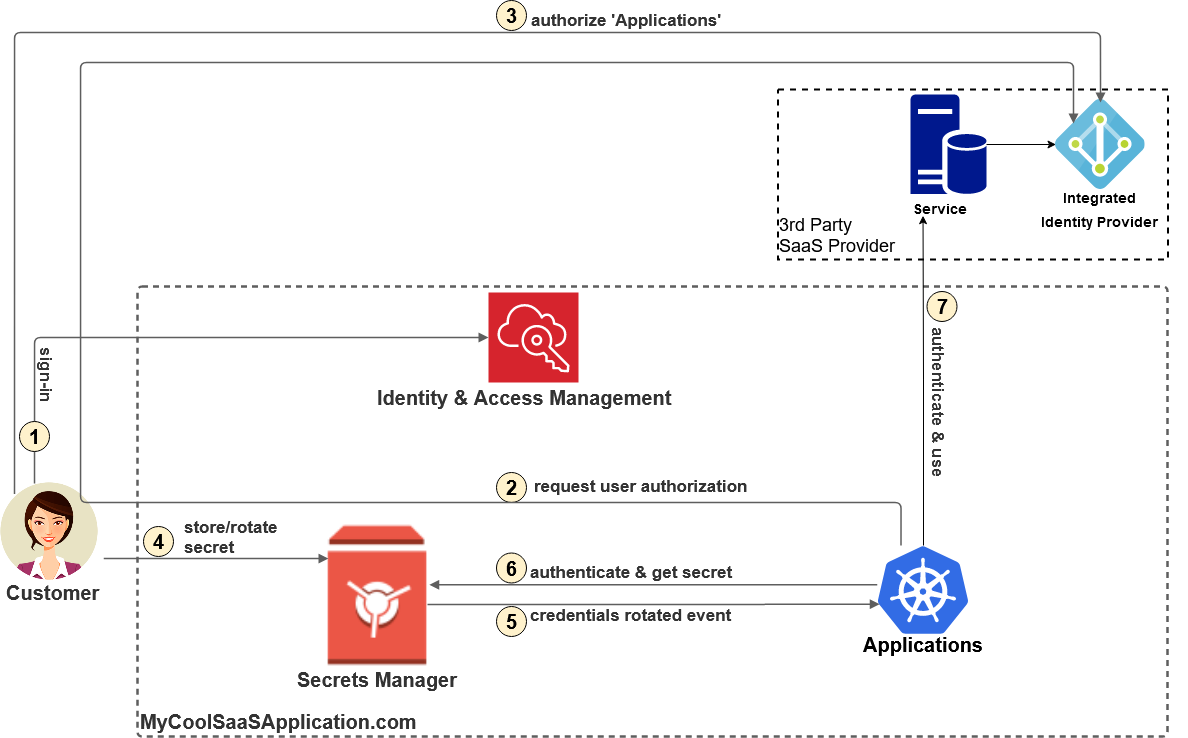


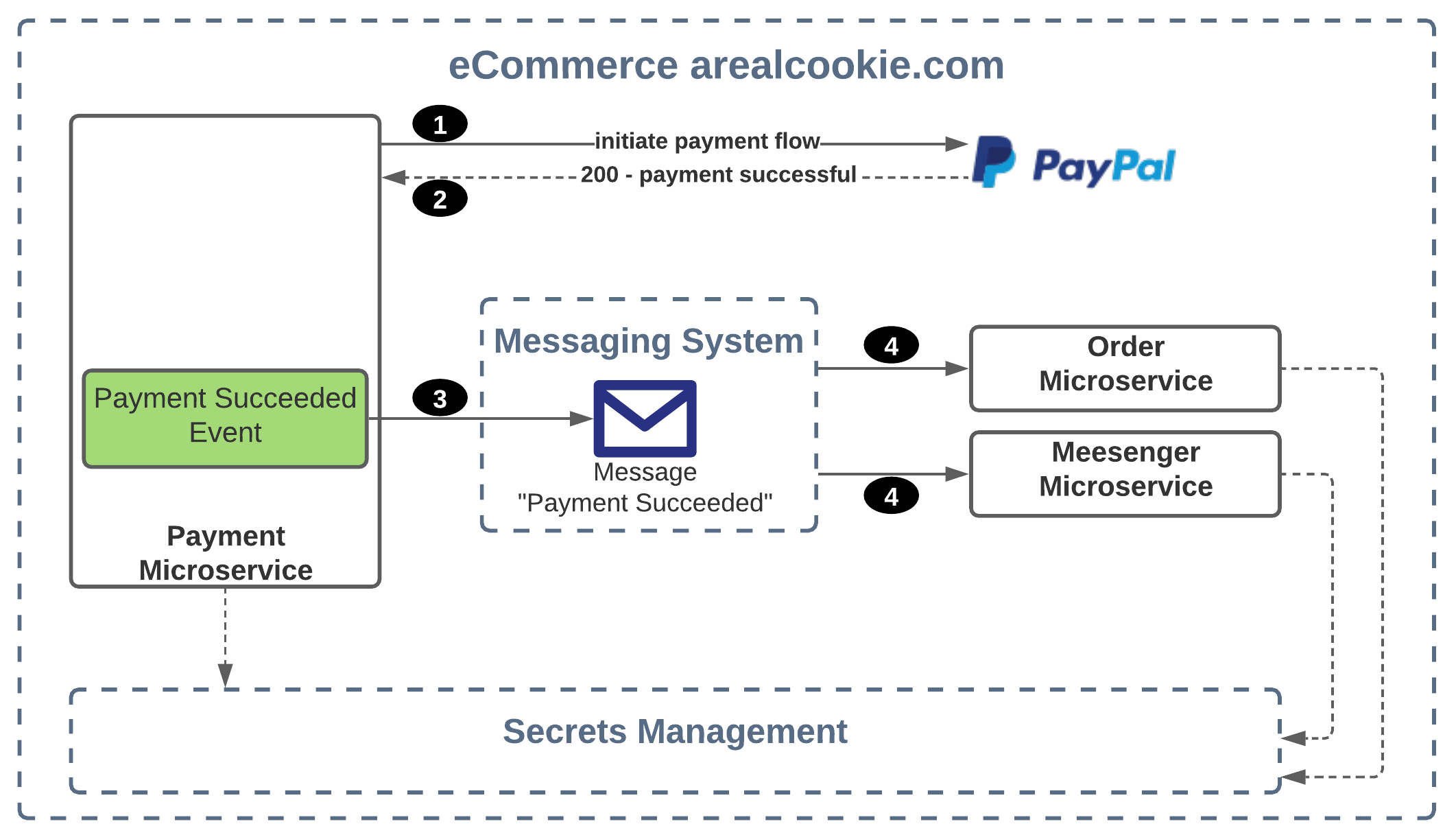




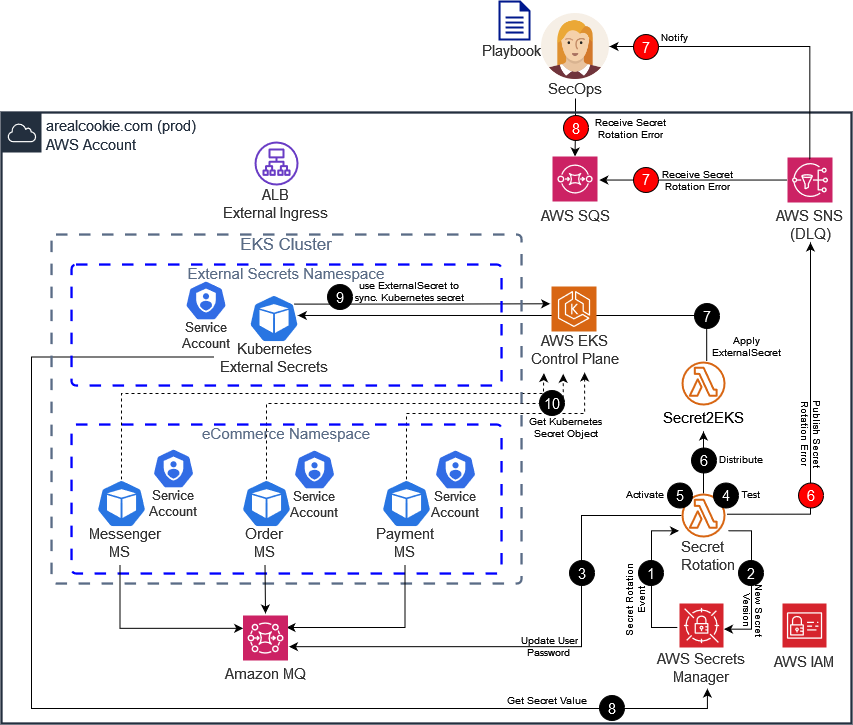


































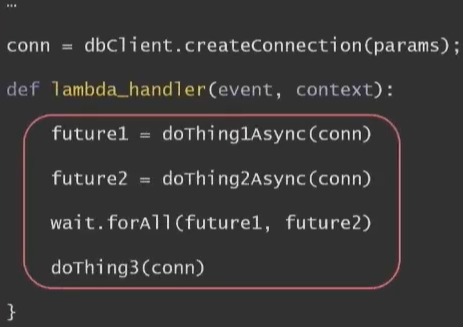
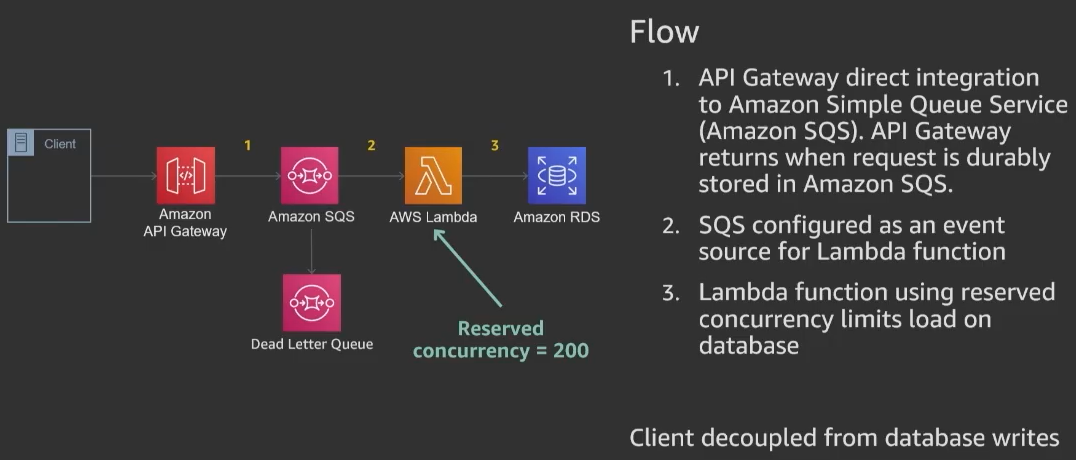
 Example – Throttling, Timeout, and exhausted database connections
Example – Throttling, Timeout, and exhausted database connections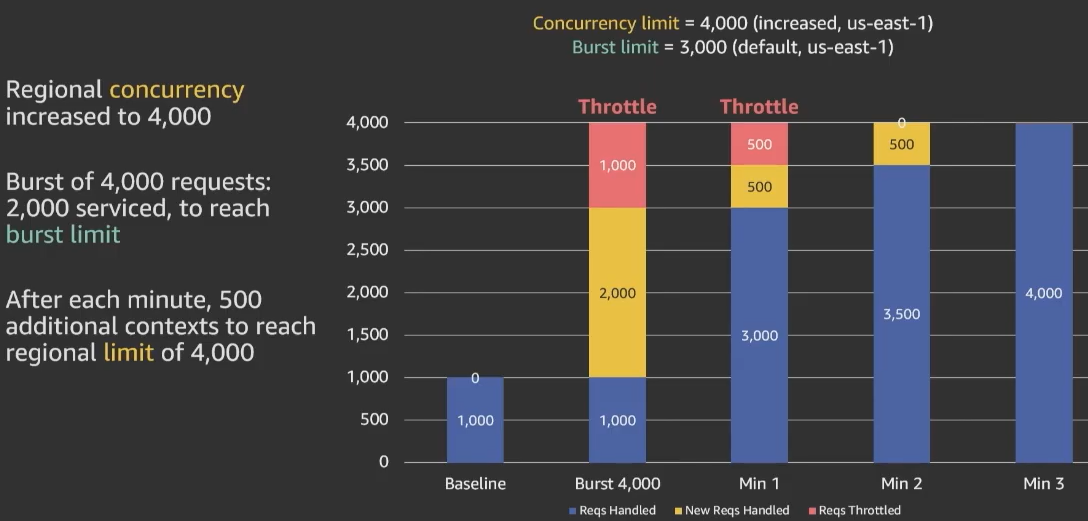
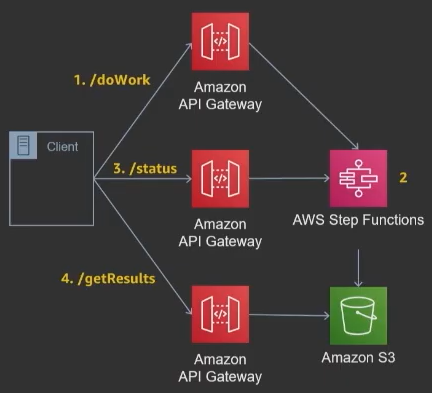
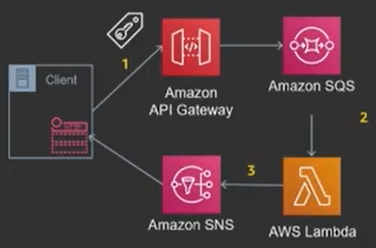
 APIs In The Front, Async In The Back
APIs In The Front, Async In The Back